
by Patrick J. Lynch
and Sarah Horton
5 Site Structure
Search Engine Optimization
When the web first rose to popularity in the 1990s, people spoke of browsing or surfing the web, and users located interesting sites primarily by finding and clicking on links listed on major web directory sites like Yahoo! and Netscape. As the size of the web has exploded over the past decade (Google now indexes well over twenty billion web pages), browsing through sites by following web links has become an increasingly inefficient means to initiate a search for new or very specific information. You may still browse the home page of the New York Times or a personal portal page like iGoogle or MyYahoo!, but if you need anything more specific, you will probably go straight to a search engine such as Google.
The way your pages appear to the automated “spider” software that search engines use to “crawl” links between web pages and create search indexes has become the most important factor in whether users will find the information you publish on the web. Search engine optimization isn’t difficult and will make your site better structured and more accessible. If your site uses proper html structural markup, you’ve already done 80–90 percent of the work to make your site as visible as possible to search engines.
Search optimization techniques are not the magic sauce that will automatically bring your site to the top of Google’s page rankings, however. seo isn’t a cure-all for an ineffective site—it can increase the traffic volume to your site and make things easier to find, but it can’t improve the quality of your site content. seo techniques ensure that your site is well formed and lessen the possibility that you have inadvertently hidden important information while constructing your site. Over the long run, though, only good content and many reference links from other highly ranked web sites will get you to the first page of Google search results and keep you there.
The long tail of web search
Most patterns of web site use follow what is widely known as long-tailed distribution. That is, a few items are overwhelmingly popular, and everything else gets relatively little attention. If you ranked the popularity of every web page in your site, you will typically see a long-tailed curve, in which the home page and a few other pages get lots of views and most others get much less traffic. This long-tailed distribution pattern in popularity is true for products in stores, books for sale at Amazon, songs to download on iTunes, or dvds for sale at Wal-Mart.
Although Wired magazine’s Chris Anderson popularized the concept of the long tail on the Internet, interface expert Jakob Nielsen first used Zipf curves (the formal mathematical term for long-tailed phenomena) to describe the distribution patterns seen in web site usage. Long-tailed usage patterns are fundamental to explaining why web search has become the most popular tool for finding information on the web, whether you are making a general Internet search or merely searching your company’s internal web site. Once users get past the home page and major subdivisions of a large site, they are unlikely to browse their way through all the links that may be required to find a specific page, even if every link is well organized, intuitively labeled, and working properly (fig. 5.8).
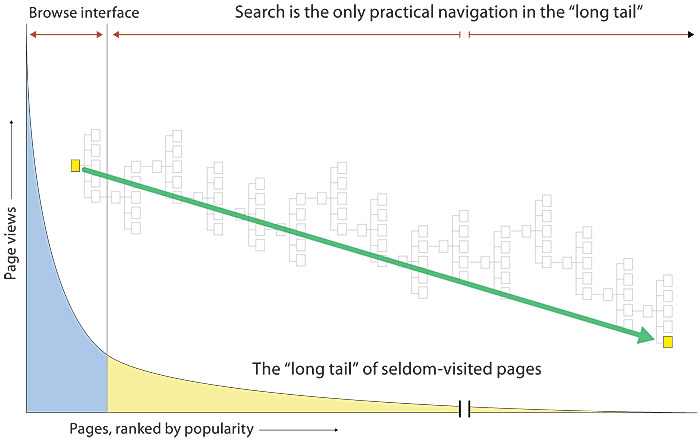
Figure 5.8 — Search is essential to finding content in large sites.
Basic search engine concepts
Links and individual web pages are the primary elements of web search. Search engines find web pages by following web links from one page to another. Search engine companies use an automated process to find and follow web links and to analyze and index web page content for topical relevance. These automated search programs are collectively called web spiders or web crawlers. This emphasis on links and pages is crucial to understanding how web search works: crawlers can find your pages only if they have links to follow to find them, and search engines do not rank web sites—they rank the popularity and content relevance of individual web pages. Each page of your site needs to be optimized for search and well linked to other pages, because from a search engine’s point of view, each page stands alone.
So, what exactly are the rules?
We can’t tell you, and the search engine companies won’t give you the formulas either. If search engines like Google and Yahoo! told everyone how they rank pages and how they detect and ban search-scamming techniques, unscrupulous web publishers would instantly start to game the system, and soon we’d all be back to the pre-Google 1990s, when general web search had become almost useless. What we can say is what the search engines themselves gladly tell web content developers: create compelling page content with proper structural markup and good linkages to other pages and sites. Don’t hide your content with poor page development techniques, and your pages will rank well in any search engine.
Internal versus external search factors
Current search engines use a combination of two information sources to rank the relevance of a web page to any given search term:
- Internal factors: characteristics of the text and links within the page—the page title, content headings, the body text, the alternate text in image html tags, web links both internal to the site and external to other sites, and the frequency and distribution of topical keywords. Organized meta-information such as keyword and description html meta tags also factor in page ranking, although not as heavily as page titles, headings, and words within the page content. Even your domain name and the names of files and directories within the url of your web page may count toward relevancy rankings.
- External factors: the degree to which your page is linked with existing highly ranked pages on the same topic, how often people who get your page in their search results click on the link to your page, and other statistical factors that the search engines glean from their own data on the searches users perform and the link choices they make for a given topic or keyword. Links from popular pages that link to your page are essentially votes that your page is relevant to the search topic. Links from high-ranking pages are the most important factor in determining rank, but overall volume counts, too: the more links your page has from other pages and the more search users who click on your page link in search engine results, the higher your overall page ranking.
When web search services became popular in the 1990s, early search engines used internal content factors almost exclusively to rate the relevance and ranking of web pages. Rankings were thus childishly easy to manipulate. By inserting dozens of hidden keywords on a page, for example, an aggressive web page author could make a page seem richer in popular topic relevance than other web pages (“sex, sex, sex, sex”).
By the late 1990s even the largest search engines were considered marginally useful in locating the best sources of information on a given topic, and the top-ranked sites were often those that used the most effective manipulation techniques to bias the search engines. The innovation that transformed web search in the late 1990s was Google’s heavy use of external page factors to weigh pages’ relevance and usefulness.
Google’s algorithms balance external ranking factors with statistical analysis of the page text to determine relevance and search ranking. Google’s fundamental idea is similar to peer citations in academic publications. Every year thousands of science papers are published: How can you tell which articles are the best? You look for those that are most frequently cited (“linked”) by other published papers. Important science papers get cited a lot. Useful web sites get linked a lot.
What search engines crawlers can and cannot “see” on your web pages
Search engine crawlers can only analyze the text, the web links, and some of the html markup code of your web page and then make inferences about the nature, quality, and topical relevance of your pages based on statistical analysis of the words on each page.
The following are not visible to a search engine:
- Display text within graphics, headers, banners, and company logos
- Flash animations, videos, and audio content
- Pages with little text content and lots of unlabeled graphics
- Site navigation that uses “rollover” or other graphic links or imagemaps
- Navigation links that depend on JavaScript or other dynamic code (crawlers do not execute JavaScript code)
- Content features such as rss feeds and other text that depend on JavaScript to appear on the page
- Microsoft Office documents and Acrobat pdf files are read by some, but not all, web crawlers, and it is not always clear how these non-html content formats affect rankings
The following may cause search crawlers to bypass a web page:
- Pages with very complex structure: deeply nested tables, many frames, or unusually complex html
- Lengthy JavaScript or css code at the top of the page html code listing: crawlers give up on a page that seems to contain no content
- Pages with many broken links: crawlers abandon pages with many broken links, and they can’t follow the broken links to find new pages
- Content with keyword spamming (repeating keywords many times in hidden text, alternate image text, or meta tags): search engines now ignore these primitive relevance-biasing schemes, and your page may even be banned from the search index if you use these techniques
- Server-side or meta-refresh redirects that are used to move a user from an old url to a new one: many crawlers don’t follow the redirect link to the new page
- Long, complex urls with special characters (&, ?, %, $) that are often generated by dynamic programming or databases
- Slow-loading pages with inefficient dynamic links to content management systems or databases: if the page doesn’t load in a few seconds, many crawlers give up and move on
- Pages that use frames or iframes: crawlers often ignore pages with complex frame schemes because they can’t make sense of the individual html files that make up each framed “page” (avoid frames where possible, and never use frames for navigation purposes)
- Some dynamic pages that are assembled on request by a web application and database; be sure your developers know how you want to handle the search visibility of your content before they choose a development technology or content management tool for dynamic web sites
In addition to making your pages less searchable, these poor practices make your site less accessible, particularly to people who use screen reader software to access web content. seo, structural markup of content, and universal usability are a wonderful confluence of worthy objectives: by using the best web practices for content markup and organizing your content and links with care, your site will be both more visible to search and more accessible to all users.
Optimizing your pages for search
Write for readers, not for search engines. The most popular sites for a given topic got that way by providing a rich mix of useful, interesting information for readers. Think about the keywords and phrases you would use to find your own web pages, and make a list of those words and phrases. Then go through each major page of your site and look at the page titles, content headers, and page text to see if your title and headers accurately reflect the content and major themes of each page.
Put yourself in the user’s place: How would a user find this page in your site? What keywords would they use to look for this content? Remember, search engines have no sense of context and no idea what other related content lies on other pages on your site. To a search engine crawler, every page stands alone. Every page of your site must explain itself fully with accurate titles, headers, keywords, informative linked text, and navigation links to other pages in your site.
Focus on your titles and keywords
The ideal optimized web page has a clear editorial content focus, with the key words or phrases present in these elements of the page, in order of importance:
- Page titles: titles are the most important element in page topic relevance; they also have another important role in the web interface—the page title becomes the text of bookmarks users make for your page
- Major headings at the top of the page (
<h1>,<h2>, and so on) - The first several content paragraphs of the page
- The text of links to other pages: link text tells a search engine that the linked words are important; “Click here” gives no information about the destination content, is a poor practice for markup and universal usability, and contributes nothing to the topical information of the page
- The alternate text for any relevant images on the page: accurate, carefully crafted alternate text for images is essential to universal usability and is also important if you want your images to appear in image search results such as Google Images and Yahoo! Images; the alternate text of the image link is the primary way search engines judge the topical relevance of an image
- The html file name and the names of directories in your site: for example, the ideal name for a page on Bengal tigers is “bengal-tigers.html”
Note that the singular and plural forms of words are different keywords, and adjust your keyword strategy accordingly. Thus “tiger” and “tigers” are different keywords. Search engines are not sensitive to letter case, so “Tiger” and “tiger” are exactly equivalent. Also think about context when you work out your content keywords. Search engines are the dumbest readers on the web: they don’t know anything about anything, and they bring no context or knowledge of the world to the task of determining relevance. A search crawler doesn’t know that Bengal tigers are carnivores, that they are large cats of the genus Panthera, or that they are also called Royal Bengal Tigers. Your optimized page on Bengal tigers might use all the following keywords and phrases, because a user could search with any of these terms:
- Tiger
- Tigers
- “Bengal Tiger”
- “Royal Bengal Tiger”
- “Panthera tigris tigris”
- “Panthera tigris bengalensis”
If your site has been on the web long enough to get indexed by Google or Yahoo!, use your chosen keywords to do searches in the major search engines and see how your site ranks in the search results for each phrase. You can also use the web itself to find data on the keywords and phrases that readers are currently using to find your site. Both Google and Yahoo! offer many tools and information sources to webmasters who want more data on how their site is searched, what keywords readers use to find their site, and how their site ranks for a given keyword or phrase:
Keyword frequency
Even in well-written content with a tight topical focus, the primary topical keywords are normally a small percentage of the words on the page, typically 5 to 8 percent. Because of the widespread practice of “keyword spamming” (adding hidden or gratuitous repetitions of keywords on a page to make the content seem more relevant), search engines are wary of pages where particular keywords appear with frequencies of over 10 percent of the word count. It is important to make sure your keywords appear in titles and major headings, but don’t load in meaningless repetitions of your keywords: you’ll degrade the quality of your pages and could lose search ranking because of the suspiciously high occurrence of your keywords.
Keyword placement on the page
There is some evidence that placing your keywords near the top and left edges of the page will (slightly) benefit your overall ranking, because, on average, those areas of pages are the most likely to contain important content keywords. The top and left edges also fall within the heaviest reader scanning zones as measured by eye-tracking research, so there are human interface advantages to getting your keywords into this page zone, too. For optimal headings, try to use your keywords early in the heading language. Search crawlers may not always scan the full text of very long web pages, so if you have important content near the bottom of long pages, consider creating a page content menu near the top of the page. This will help readers of long pages and will give you an opportunity to use keywords near the page top that might otherwise be buried at the bottom (fig. 5.9).

Figure 5.9 — Write your major titles and navigation elements so that they fall within the “golden triangle” (shown in yellow) or the “F pattern” of reader visual scanning (shown in red).
Use plain language and keywords in file and directory names
Use your major topical keywords in your file and site directory names. This helps a bit with search optimization, and it makes the organization of your site much more understandable to both your users and your partners on the web site development team. Always use hyphens in web file names, since hyphens are “breaking” characters that divide words from each other. For example, in the file name “bengal-tiger-habitat.html” a search engine will see the words “Bengal,” “tiger,” and “habitat” because the words are separated by hyphens. If you use “nonbreaking” underscore characters as dividers or run the words together, the file name is seen as one long nonsense word that won’t contribute to page ranking. The file names “bengal_tiger_habitat.html” or “bengaltigerhabitat.html” are equivalent, and neither is ideal for most search engines.
Both your readers and search crawlers can easily make sense of plain-language directory and file names in your urls:
something.edu/cats/tigers/bengal-tiger-habitat.html
Requesting links from other web sites
Requesting links from established, high-traffic web sites is crucial to search optimization, particularly for new web sites. These links weigh heavily in search engine rankings, so they are well worth the effort to establish. If you work within a larger company or enterprise, start by contacting the people responsible for your primary company web site and make sure that your new site is linked from any site maps, index pages, or other enterprise-wide directory of major pages. Although it may not always be possible, the ideal link would be from your company’s home page to your new site. Smart company web managers often reserve a spot on the home page for such “what’s new” link requests because they know how to leverage their existing search traffic on the home page to promote a new site. The link does not have to be permanent: a few weeks of visibility after your site launches and gets an initial pass from the major search crawlers will be enough to get you started.
Your company’s central web organization will also likely be responsible for any local web search capabilities, and you want to be sure they are aware of your new web site, particularly if it is housed on a new web server. Create a standard press release or email announcement, and send the announcement to colleagues, professional associations, partner companies, and the local press, requesting that related sites link to your site. The more links your site gets from established, high-traffic sites that already rank well in Google or Yahoo!, the faster your site will climb the search results rankings.
Submitting your new site to the major search engines
By far the best way to get your site listed in the major search engines is to request links from other existing sites that point to your new site. The two largest search engines offer pages that allow you to submit the url for a new web site, but there is no guarantee that the search crawlers will find your site immediately. It could take several weeks or more for them to visit your new site and index it for the first time.
Site submissions pages:
HTML meta tags
Meta tags are a great intellectual notion that has largely fallen victim to human nature. The basic idea is excellent: use a special html header designation called a “meta” tag to hold organized bits of meta-information (that is, information about information) to describe your page and site, who authored the page, and what the major content keywords are for your page. The information is there to describe the page to search engines but is not visible to the user unless he or she uses the browser “View Source” option to check the html code. Unfortunately, in the 1990s, search scammers began to use meta tags as a means to load in dozens or even hundreds of hidden keywords on a page, often in many repetitions, to bias the results of web searches. Because of these fraudulent practices, recent generations of search engine software either ignore meta tags or give them little weight in overall search rankings. Current search crawlers will also down-rank or ban pages that abuse meta tags, so the practice of abusing meta tags has become pointless.
Should you use meta tags on your pages? We think they are still a useful structured means to provide organized information about your site. And although search engines may not give heavy ranking weight to meta tag information, most search engines will grab the first dozen or so words of a “description” meta tag as the descriptive text that accompanies your page title in the search results listing.
The basic forms of meta tags are useful, straightforward to fill out, and cover all the basic information you might want to describe your page to a search engine:
<meta name="author" content="Patrick J. Lynch" />
<meta name="description" content="Personal web site of artist, author, designer and photographer Patrick J. Lynch." />
<meta name="keywords" content="web design, web style guide, yale university, patrick j. lynch" />
The bottom line on meta tags: they never hurt, they might help a little, and they are a simple way to supply structured meta-information about your page content.
Make your site easy to navigate
Basic navigation links are an important part of search optimization, because only through links can search crawlers find your individual pages. In designing your basic page layout and navigation, be sure you have incorporated links to your home page, to other major subdivisions of your site, and to the larger organization or company you work in. Remember, each link you create not only gives a navigation path to users and search engine crawlers but associates your local site with larger company or other general Internet sites that have much higher user traffic than your site. The more you use links to knit your site into your local enterprise site and related external sites, the better off you’ll be for search visibility.
Two kinds of site maps
In the context of search optimization, the term “site map” has several meanings, depending on its context:
- Site map pages: most web site maps are ordinary web pages with lists of links to the major elements of your web site (fig. 5.10). These master lists of the major pages in your site are an excellent resource for search engine crawlers, and site map pages are a great way to ensure that every important page of your site is linked in a way that search crawlers and users can easily find. Site map or “index” pages are a common element of web sites, and users who prefer to browse through lists of links know to look for site map or index pages in a well-organized site. In the earlier days of the web you’d see site maps that were laid out as diagrammatic charts or visual maps of the site, but the highly visual site map metaphors have largely faded in favor of the much more efficient link lists.
- xml site maps for search engines: the second common meaning for “site map” refers to a text file in xml format that sits at the level of your home page and informs web search crawlers about the major pages in your web site, how to find the pages, and how often the pages are likely to be updated (daily, weekly, monthly).
You should use both kinds of site maps to ensure maximum visibility of your site content.







